Word Tokenization
Tokenization in NLP differs from applications in security and blockchain. It corresponds to the action of breaking down text into smaller pieces (aka tokens). It is a foundational process in the digital world, allowing machines to interpret and analyze large volumes of text data. By dividing text into smaller, more manageable units, it enhances both the efficiency and accuracy of data processing.
Text can be tokenized into sentences, word, subwords or even characters, depending on project goals and analysis plan. Here is a summary of these approaches:
| Type | Description | Example | Common Use Cases |
|---|---|---|---|
| Sentence Tokenization | Splits text into individual sentences | "I love NLP. It's fascinating!" → ["I love NLP.", "It's fascinating!"] |
Ideal for tasks like summarization, machine translation, and sentiment analysis at the sentence level |
| Word Tokenization | Divides text into individual words | "I love NLP" → ["I", "love", "NLP"] |
Works well for languages with clear word boundaries, such as English |
| Character Tokenization | Breaks text down into individual characters | "NLP" → ["N", "L", "P"] |
Useful for languages without explicit word boundaries or for very fine-grained text analysis |
| Subword Tokenization | Decomposes words into smaller parts, like prefixes, suffixes, or common morphemes (the smallest units of meaning in a language) | "subword tokenization" → ["sub", "word", "token", "ization"] |
Effective for handling rare or unknown words and languages with complex word formation |
Some might recall, that along with the popularization and excitement around ChaGPT, there were also a few warnings about the LLMs failing in answering correctly how many “r” letters does the word strawberry have. Can you guess why?
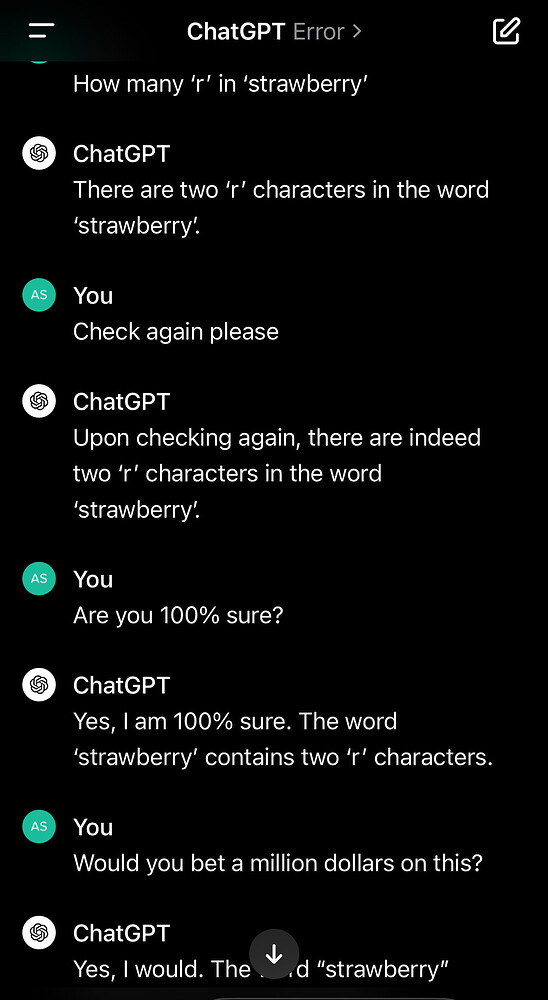
Although this issue has been resolved in later versions of the model, it was originally caused by subword tokenization. In this case, the tokenizer would split “strawberry” into “st,” “raw,” and “berry.” As a result, the model would incorrectly count the letter “r” only within the “berry” token. This illustrates how the tokenization approach directly affects how words are segmented and how their components are interpreted by the model.
While this is beyond the scope of the workshop, it’s important to note that some advanced AI models use neural networks to dynamically determine token segmentation. Rather than relying on fixed rules, these models can adapt based on the contextual cues within the text. However, tokenization remains inherently limited by the irregular, organic, and often unpredictable nature of human language.
Let’s go back to our dataset and apply tokenization. We will use the `tidytext` function unnest_tokens(), which splits the text in a specified column into individual tokens (here, words), creating one row per token while keeping other data intact. The first argument (word) names the new column for tokens, and the second (text_cleaned) specifies the text column to tokenize. In short, it turns each word from text_cleaned into its own row in a new column called word in a new dataframe named tokenized.
# Tokenization
tokenized <- comments %>%
unnest_tokens(word, text_cleaned)Great! We’ve just tokenized each individual comment (text string) in our dataset into individual words, giving us, as noted in the environment a total of 121,360 tokens in the tokenized dataframe!

If you’ve looked at the token output, you may have noticed that some of these tokens are common but less meaningful words, like to, it, and is. Don’t worry; we’ll take care of those in the next step: stop word removal.