Performing Data Transformations
Now that we have learned a few things about data types and facets we will dive a little deeper on how we can use them to streamline some transformations to make our data tidy.
Common Transforms
OpenRefine provides a range of common transformations that help users structure and standardize their datasets. We can perform very simple to more advanced transformations. Besides transforming data types, we can change text cases, trim whitespaces, split and join values and find and replace text and much more.
For instance, we can change type values movie and show to lowercase. Or we could apply the collapse consecutive whitespace transformation to the description column. This function will remove all space characters that sit in sequence and replace them with a single space. Let’s try it and see what we get!
Clustering
Remember we have several entries for the same streaming service but with some variations? Editing those values for deduplication manually could take us too much time.
Now, let’s move to the streaming column. We want to keep six unique values in a simplified choice in title case: Amazon, Apple, Disney, Max, Netflix and Paramount. We can use the Edit cells > Common transforms > To titlecase and we end up with less choices, saving us quite some clicks and edits.
Clustering helps you find and merge similar but inconsistently written values. It’s super useful when you have messy data — think entires like: “New York”, “new york”, “NewYork”, or “N.Y”. You know they’re referring to the same location — but the computer doesn’t, unless you help it out. OpenRefine offers two main methods to resolve these type of issues.
Key Collision Methods
These methods simplify the data to make it easier to compare. They look for basic patterns (like removing spaces, turning everything into lowercase, or sorting words alphabetically) to figure out if two things are similar.
Think of it like simplifying everything to a “core” version and then checking if the core versions match.
Example: “Apple Inc.” and “INC. Apple” will both be simplified to the same “core version” and grouped together.
Nearest Neighbor Methods
These methods directly compare the values to see how similar they are. They measure how much you’d need to change one value to turn it into the other (like fixing typos or small differences).
Think of it like checking each pair of values closely and asking, “How different are these from each other?”
Example: “Micheal” and “Michael” are compared and seen as very similar because they only differ by one letter.
Most Common Clustering Methods
| Method | Category | Description | Good For | Example |
|---|---|---|---|---|
| Fingerprint | Key Collision | Lowercases, removes punctuation, sorts words alphabetically | General cleanup of similar words | John Smith = Smith John |
| Ngram-Fingerprint | Key Collision | Like Fingerprint but uses chunks of letters (n-grams) | Catching typos and small variations | Jon ≈ John |
| Metaphone3 | Key Collision | Groups words that sound alike using English phonetics | Names, brand names | Katherine ≈ Catherine |
| Levenshtein Distance | Nearest Neighbor | Counts how many single-character edits are needed to match two strings | Short strings with typos | Jon ≈ John, color ≈ colour |
| PPM (Prediction by Partial Matching) | Nearest Neighbor | Uses letter patterns to guess similarity based on character prediction | Very short strings, abbreviations | NY ≈ New York (sometimes) |
In the facet we have open for the column streaming, click Cluster to check available options. It should prompt the following:
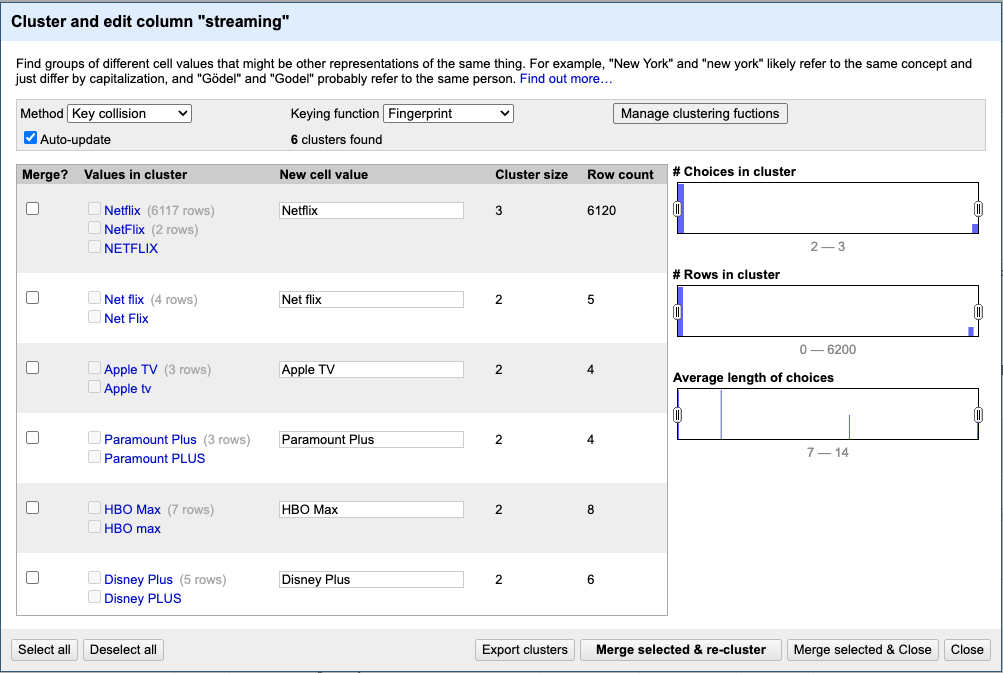
OpenRefine initially identified 6 clusters using the default method. However, switching to the Nearest Neighbor clustering method with the Levenshtein distance function would be more effective in capturing clusters that reflect spelling variations present in our dataset.
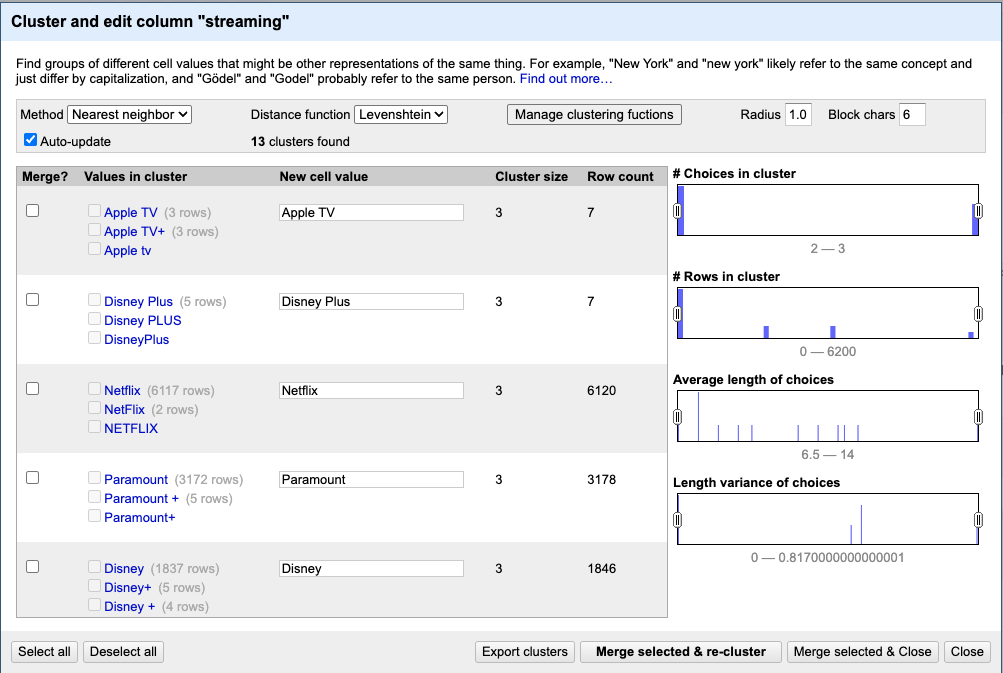
Awesome! OpenRefine has identified 13 clusters and provides some helpful options to easily harmonize and merge them. You can select the clusters you want to merge and enter the desired standardized value—for example: Amazon, Apple, Disney, Max, Netflix, and Paramount.
Once you’re ready, click Merge Selected & Re-cluster rather than Merge & Close. We recommend this because re-clustering can help OpenRefine detect additional clusters you might want to merge.
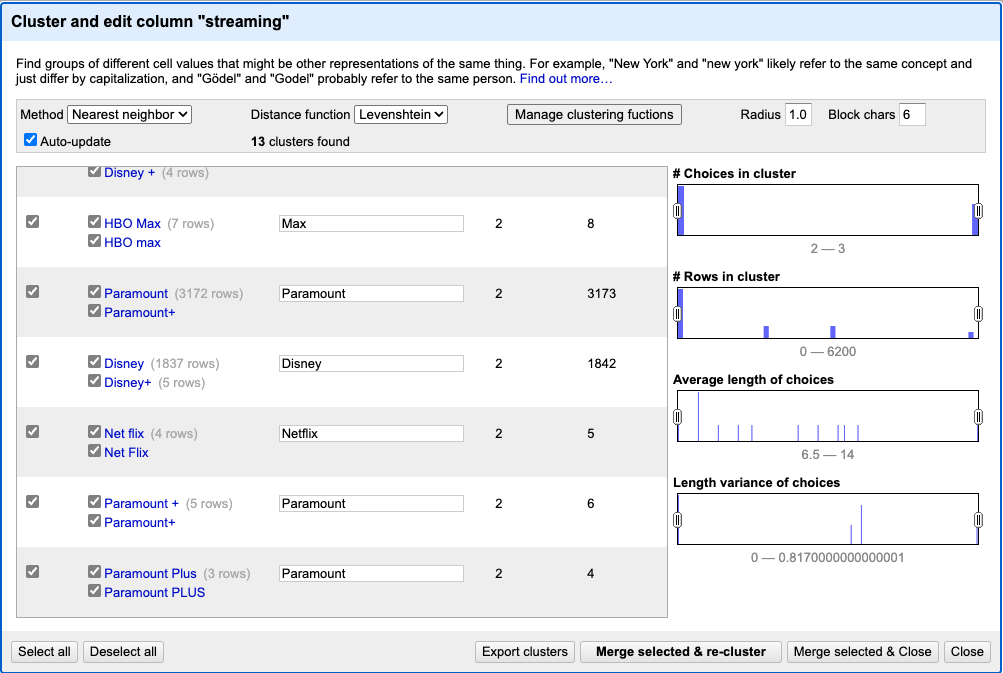
This step should reduce the total number of distinct values to 9. However, there will still be some uncleaned entries remaining for three of the streaming services.
Navigate the same method Nearest Neighbor and check which options could help the clustering for Amazon.
This method uses a parameter called radius which represents a distance threshold and controls how close or similar things have to be in order to be considered a match. The default is set as 3.0 but if we increase it to 6.0 it will be less strict and find more potential matches. For example:
“Jon” and “John” might match at 6.0, but not at 3.0.
“Jon” and “Jonathan” would likely only match with a larger radius like 6.0.
For our Amazon example it will work just fine since we don’t other competing streaming services with similar names. Now that we have stretched the radius, let’s merge those clusters accordingly.

Wait, we are not ready just yet, notice that we have two entries for the same streaming service HBO and Max. In this case we need to manually change them, since it is a easy fix, and no clustering method would be able to pair these values accordingly.
While we could spend much more time delving into the variety of clustering methods and their nuanced differences, that level of detail falls into more advanced territory. The best approach often depends heavily on the nature of your data and the specific goals of your analysis. For those interested in exploring further, we recommend reviewing the official documentation of the clustering algorithms you’re considering and consult with us if you have any questions.